
AI-Powered Knowledge Maps for Navigating Unstructured Data
Investigations often involve analyzing large document sets–from text such as emails to audio and video content–and the amount of pertinent content keeps exploding. Twenty years ago, the investigation into the Enron scandal included a total of a half a million documents. Today, a large organization typically generates that number of documents in just a few days. If a human must read each document and manually extract and cross-reference all the details of interest, finding specific insights or even settling on the right questions to ask simply becomes impossible. So how can information buried in such large masses of unstructured data be brought to light? One solution is to support an iterative discovery process which can spotlight important information. While narrowing down the pool of relevant documents, this approach still supports the discovery of new questions.
AI-assisted knowledge mapping
By integrating recent advances in large language models (LLMs) with graph data technology, it’s possible to build a knowledge map from unstructured content that enables rapid exploration and modification of data from varied sources.
Kineviz has recently been implementing these ideas in a new SightXR product designed to work seamlessly with our Kineviz visual analytics platform. We can now easily engage with unstructured data to:
Automatically tag topics of interest, which drastically narrows the scope of the information to be reviewed in a document set.
Create a knowledge map to enable fast data navigation.
Perform keyword search and semantic search to find relevant information and patterns.
Engage with data via Question-and-Answer (chat) or Summarization.
Relationships and entities within and across documents can then be accessed through keyword search or semantic search using a natural language question and answer format. Data from any source can be used as input, and the identity of data sources retained to enable evaluation of results for accuracy and reliability.
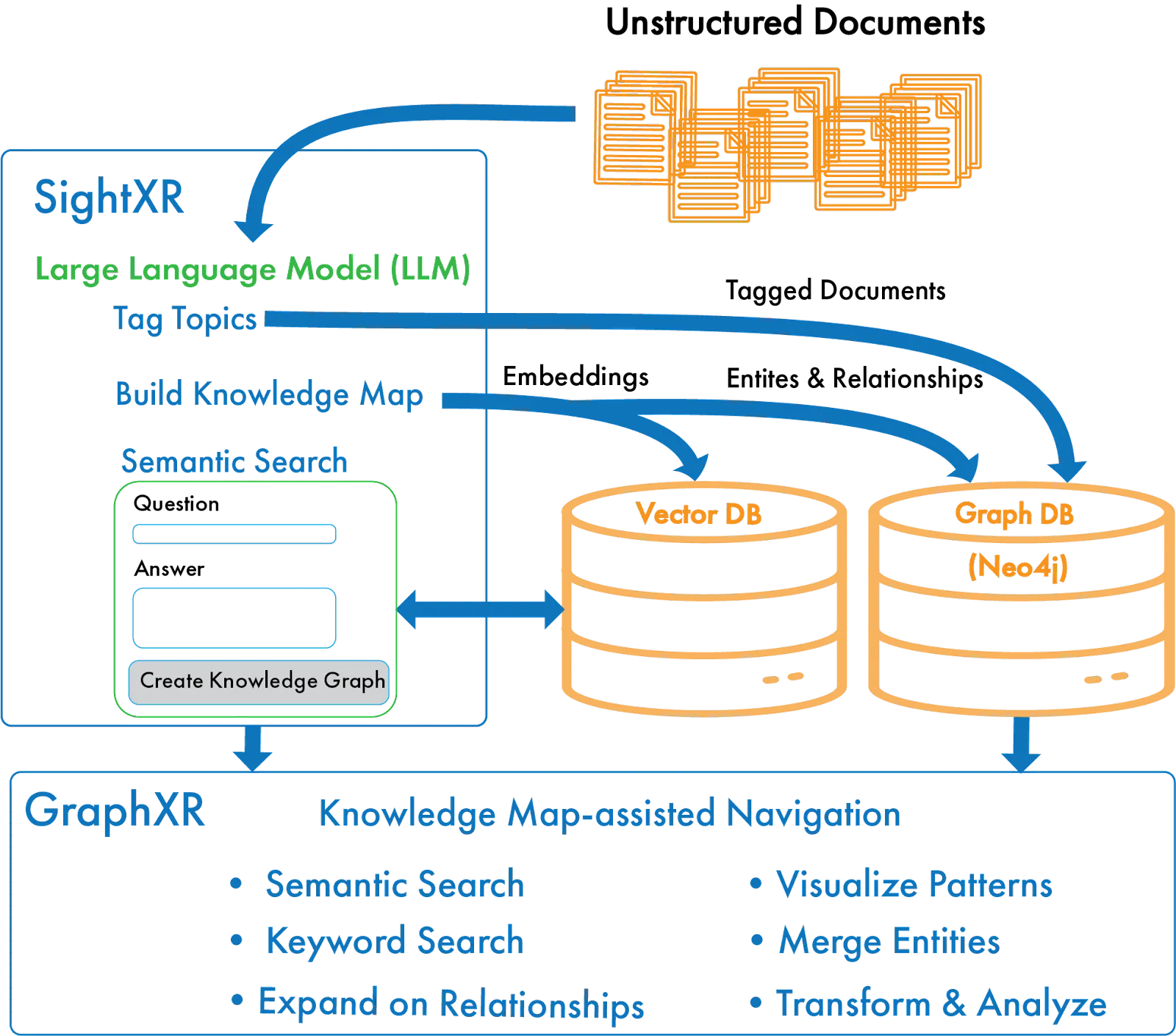
The architecture includes a data pipeline which allows for processing of different kinds of unstructured data, leveraging a large language model (LLM) to recognize entities and relationships and enable semantic search. We store the extracted entities and relationships in a graph database such as Neo4j, and the embeddings for semantic search in a vector database.
Knowledge map-assisted navigation
The knowledge map becomes a starting point for navigating the data to spotlight answers to specific questions of immediate interest. We start with a general mapping because in most cases, it’s impractical and unnecessary to build a true knowledge graph that tags and connects all the information in a large unstructured document set. What’s most often needed is a way to reveal which documents hold information of immediate interest, and a way to investigate that information in more detail. From the knowledge map, a human can quickly narrow down an investigation using natural language question and answer format, and then expand upon elements that are deemed important.
Detailed knowledge graphs based on chat answers are then constructed automatically for rapid visualization using Kineviz layouts, analytics, and transforms. By limiting the LLM-powered semantic search exclusively to a mapped document set, the risk of hallucination is effectively eliminated.
Document nodes can be pulled directly from the graph database into Kineviz via full text search and the ability to click and expand on relationships. For example, in a public archive of emails related to the Enron bankruptcy litigation, names of people have been encoded as nodes in the knowledge map, and connected to email document nodes through a MENTIONS relationship. Selecting a specific Person node and expanding on its MENTIONS relationships brings just those connected email document nodes into the graph.
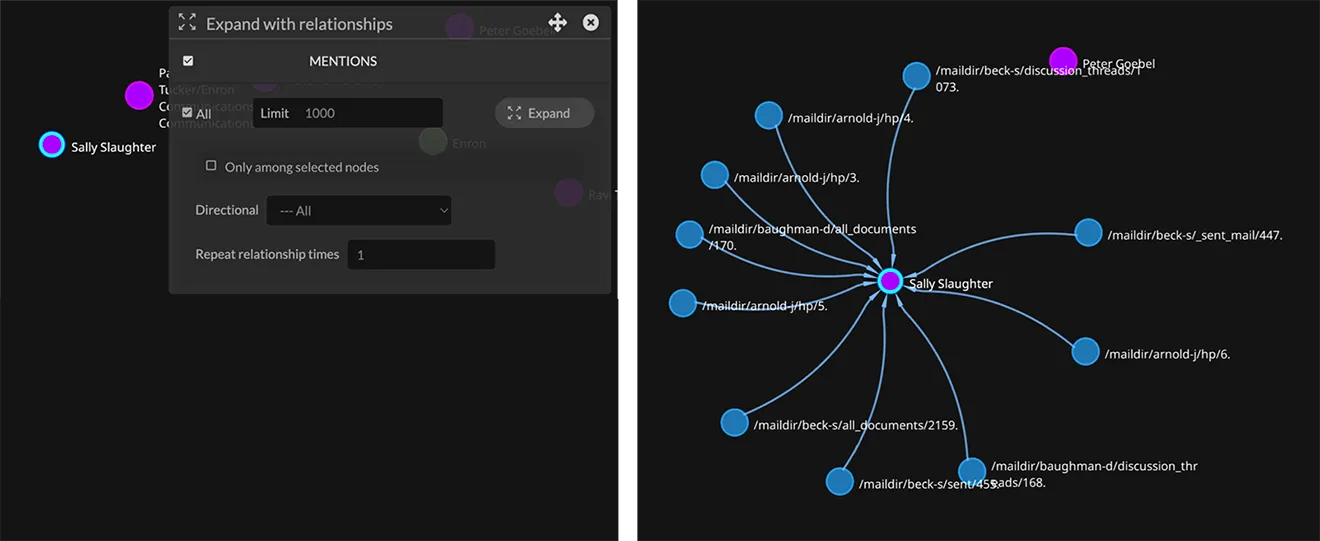
As knowledge becomes available in the map, Kineviz enables a wide variety of graph analytics. For example, pagerank values can be generated with one click to reveal important relationships that might otherwise not be apparent. And Kineviz’s many selection, display, and layout options support the ability to highlight and quickly isolate patterns of interest.
Conclusion
We find that an application built on LLM capabilities provides an essential missing link for creating focused, explainable discovery of patterns in unstructured data at unprecedented speed. LLMs are the key to automatic parsing of entities and relationships, building a general knowledge map, and enabling natural language query. Iterative exploratory analysis in a visualization environment such as Kineviz then provides the means to rapidly spotlight insights that would otherwise remain hidden.