
How to create a Knowledge Map from 500k email messages using LLM
Email correspondence holds key information about what has happened in a business, and crucially, who was responsible for key decisions. But for most enterprises, there’s simply too much email. A human cannot read through it all, extract relevant information, and discover key connections in any reasonable amount of time. Also, any solution needs to be interactive and explainable: we want to be able to zoom out and get a sense of everything and also zoom in to individual emails.
In this post, I’ll show how we generated an explainable, interactive knowledge map from 500,000 publicly available email messages in under 12 hours.
We used Kineviz SightXR, which lets a user
define the entities and relationships of interest (that is, an ontology or schema),
apply the schema to documents in bulk to build a knowledge map in the form of a connected graph, and
immediately build the knowledge map for exploration.
A knowledge map makes it possible to connect a large amount of related information and navigate through it efficiently. It helps us focus on one thing at a time, because information is encoded into nodes and edges which have a sense of space. Nodes have a size and position, and edges represent the connections between nodes, and this serves to cluster in space the nodes which are related. In that sense, 3D graph representation is akin to how we think and move through the physical world–an embodied way of working with data.
SightXR knowledge mapping captures specific entities of interest and their relationships, yet preserves visibility into source documents. That’s important, because while Large Language Models (LLMs) can be used to extract information efficiently, we also have to be able to explain and validate the results.
Building the Knowledge Map
The Enron corpus is a useful starting point for bulk analysis of text, since it contains over 500k email messages generated by 158 corporation employees over a period of several years. It’s open to public use, and is conveniently in CSV format.
SightXR provides a step-by-step interface to guide the user through the necessary tasks.
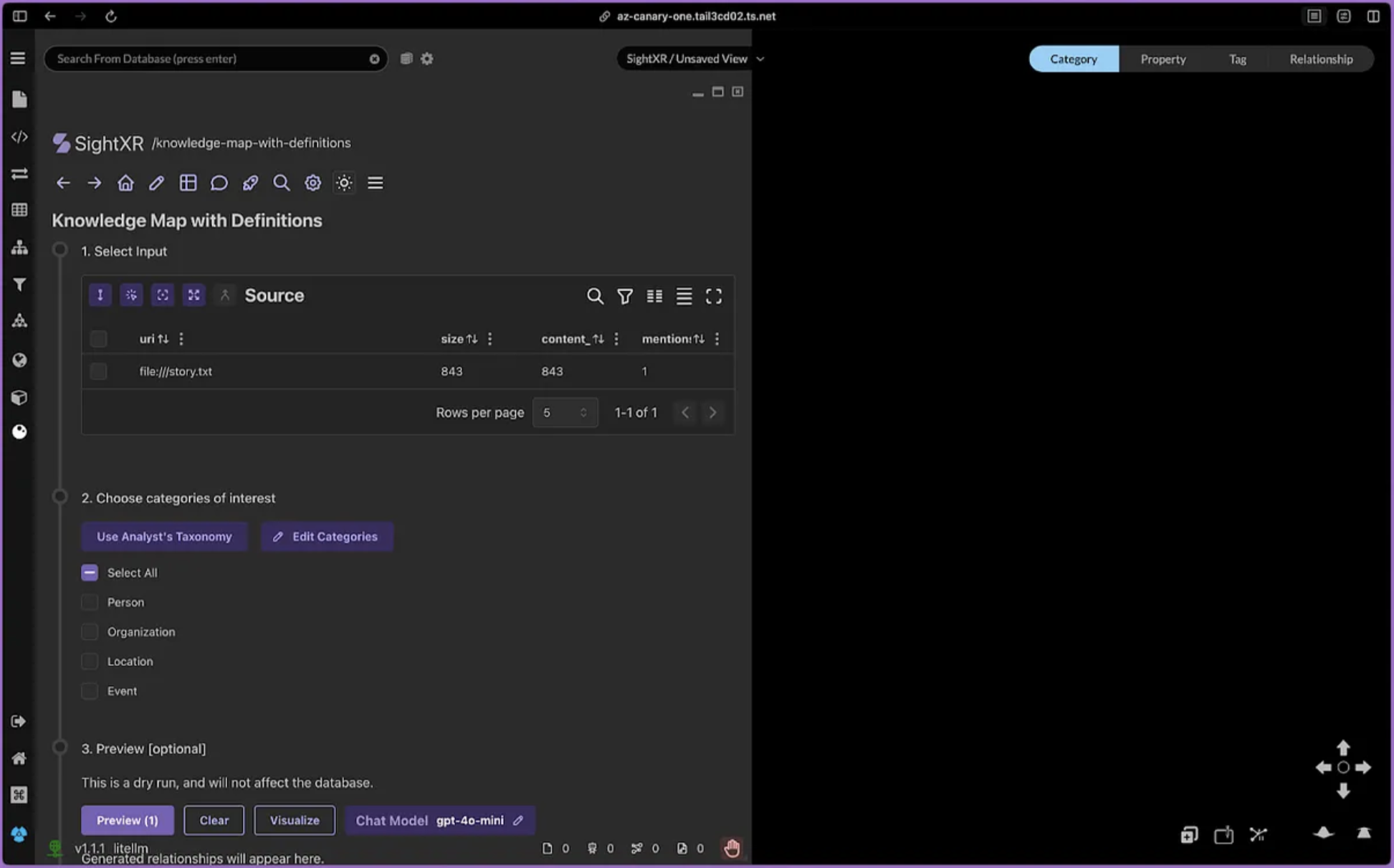
First, we created a knowledge map from the 500k Enron emails overnight using SightXR. Enron data includes the email messages, and email addresses of the sender and receivers.
A schema for the entities and relationships extracted for our initial Enron knowledge map is shown below. In general, entities can be things like Persons, Organizations, Locations, and Events, and the relationships that connect entities can describe information like “Alice KNOWS Bob”.
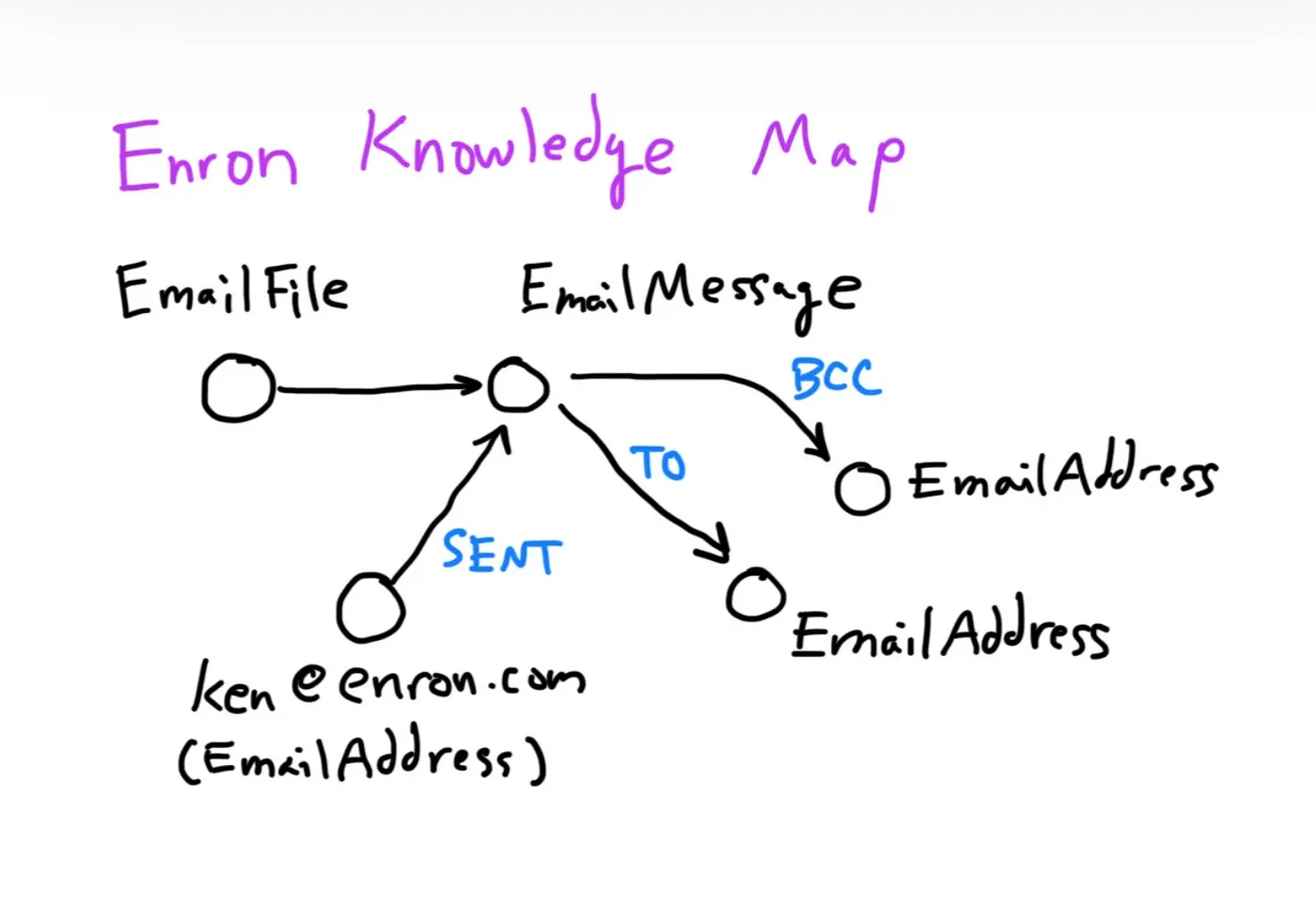
Each row of the source csv has a `filename` and `message`. For each message, we ask gpt-4o-mini to “Find relationships involving entities of types Person, Organization, Location, Event in the text provided.” We also use some basic email parsing code to extract the email addresses involved in the message.
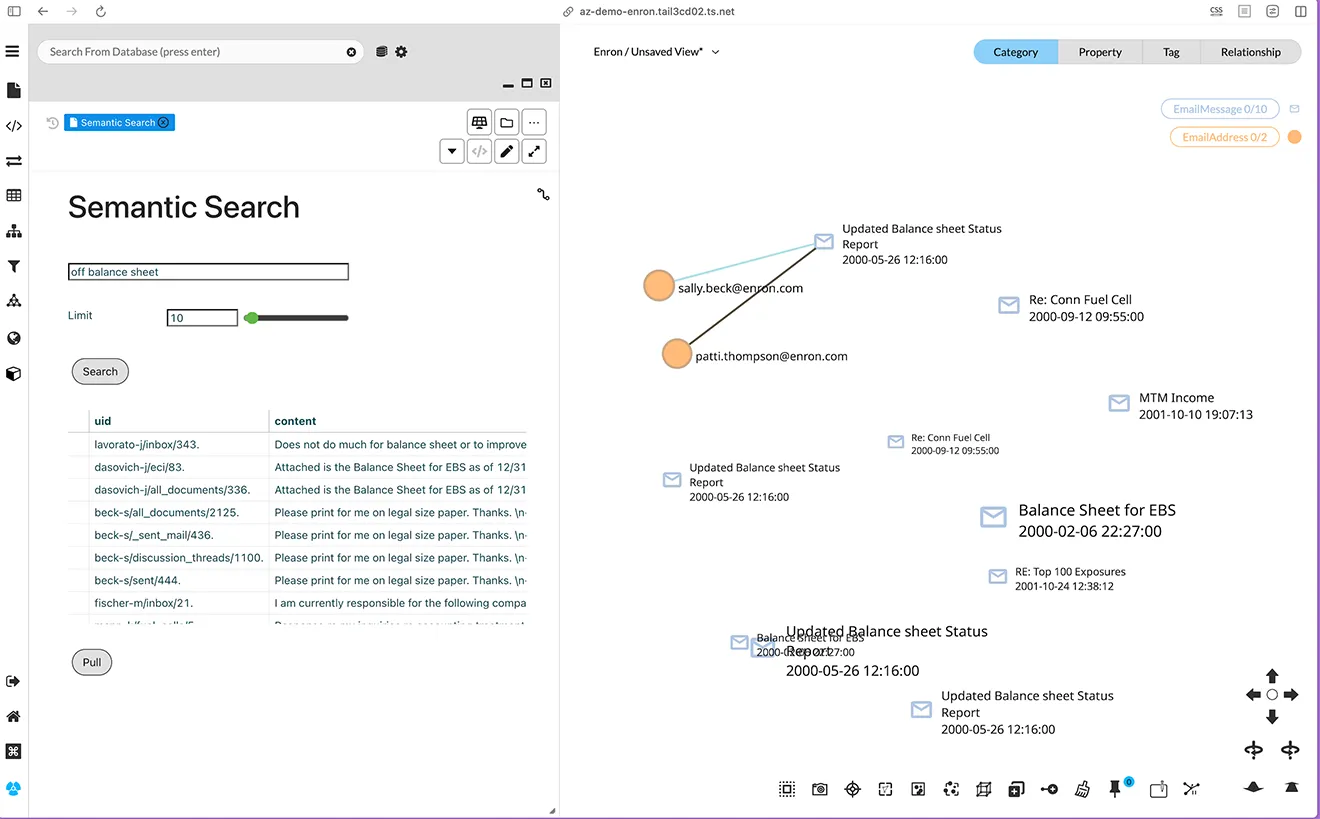
With the resulting knowledge map in place, we added Semantic Search, which enabled fuzzy search over everything.
Finally, we implemented a Classification workflow, to filter emails by criteria like “discusses the company’s future strategy”.
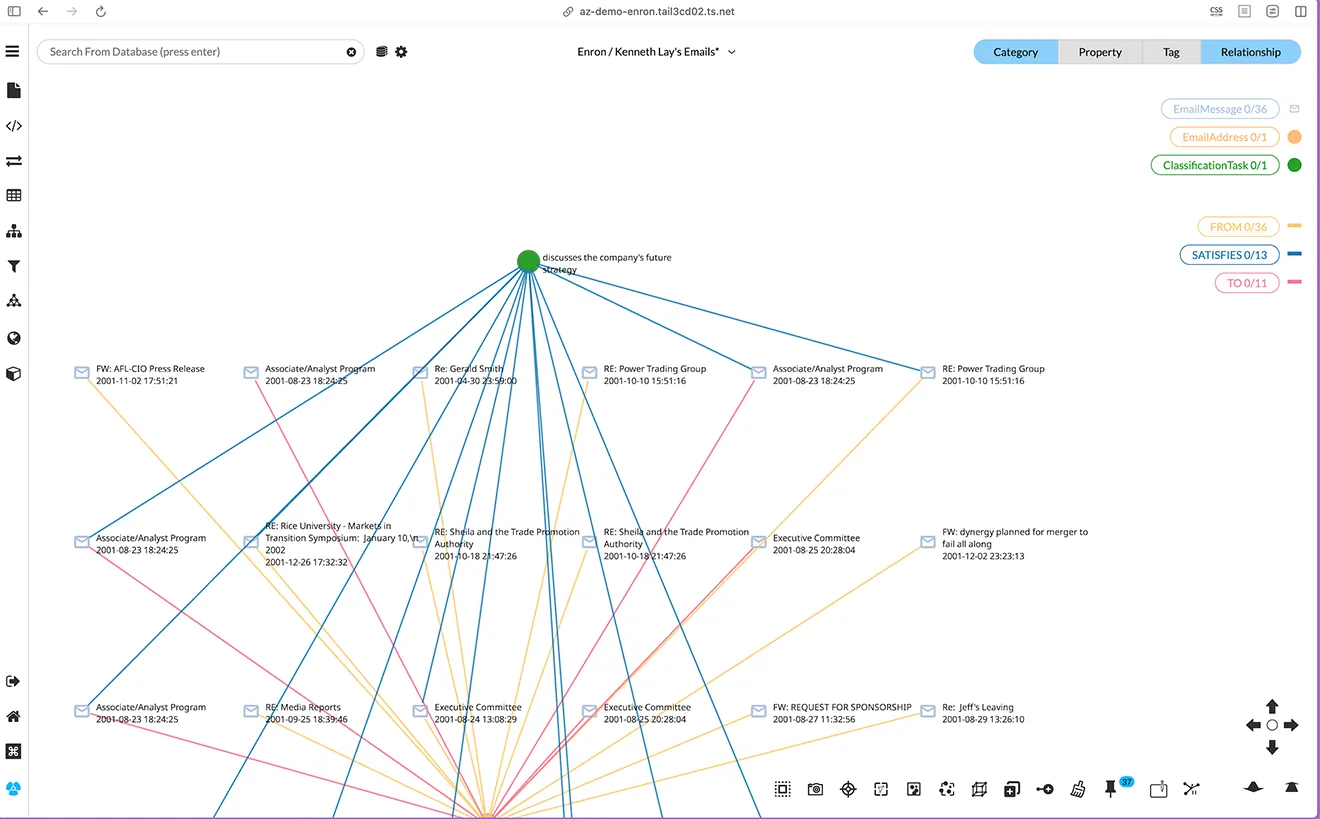
Classifying emails if they match “discusses the company’s future strategy”
The resulting knowledge map lets us explore the connections in the knowledge map, and review the topics as well as the actual emails involved.
For the technically adept out there, I’ve listed some of the technologies we used.
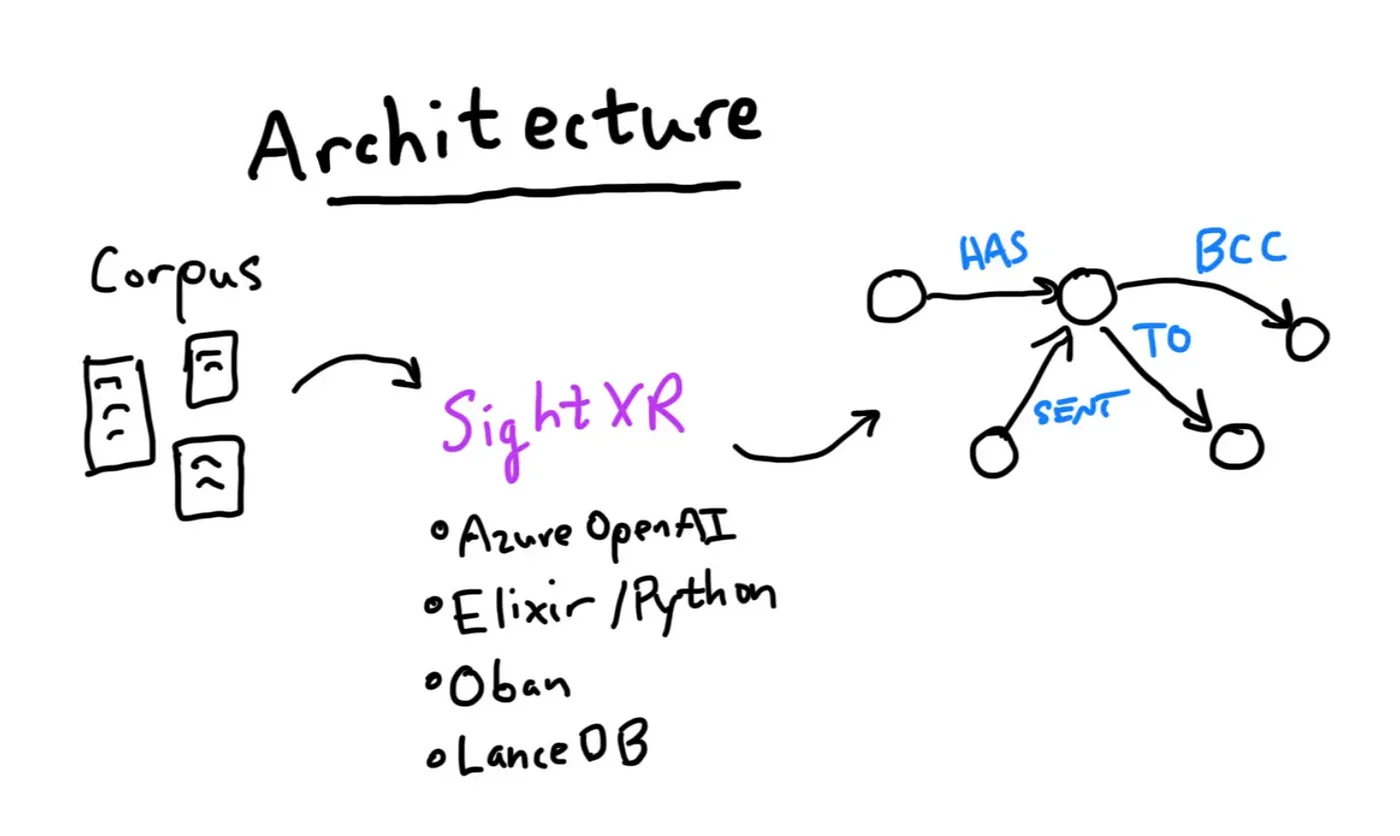
Basic architecture of the email ingestion pipeline
In essence, Elixir / Oban enable high worker count and rate limiting by distributing one LLM request per worker. I chose Elixir because it makes it easier to write highly concurrent programs with lightweight “processes” (BEAM process). The Oban framework for Elixir made it easy to queue up hundreds of thousands of jobs to process each email message, one by one.
Azure OpenAI’s gpt-4o-mini deployments allow 2 million tokens per minute, which sounds like a lot but can quickly be used up. We used two of those. To avoid rate limit errors, I configured Oban to allow only 150 in-flight LLM requests at a time. Elixir’s lightweight processes made it possible to have such a high worker count. On the other hand, I was running into memory limits with my Python / python-rq / supervisord implementation, because of more heavyweight processes used by each Python worker. I couldn’t launch 150 Python workers, because of the memory consumed by the libs loaded in each worker.
Parsing Email Chains
After exploring the initial knowledge map, we also wanted to extract the “chain”, or sequence of email messages embedded within each individual email file. For example, a single row of the Enron csv might contain a thread of 4 messages, with complex reply / forward relationships. Such chains give a better sense of the dynamics of the communication: who was driving the conversation, who was included, and at what point in time.
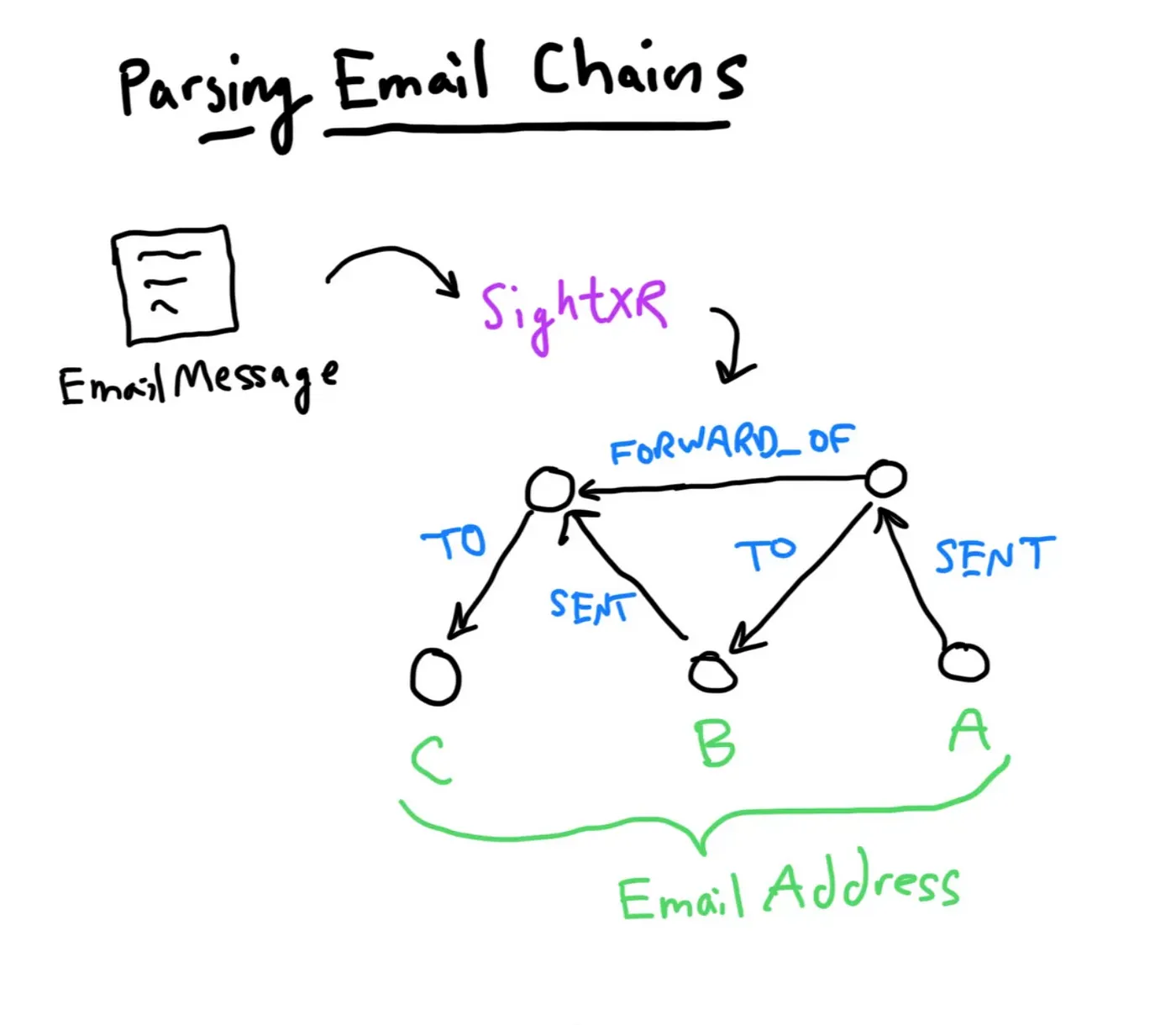
Advanced: parsing email chains
Parsing these deterministically from the Enron csv seemed daunting, so we used gpt-4o to manage that. The resulting knowledge map makes it possible to investigate communication over time among key Enron employees.
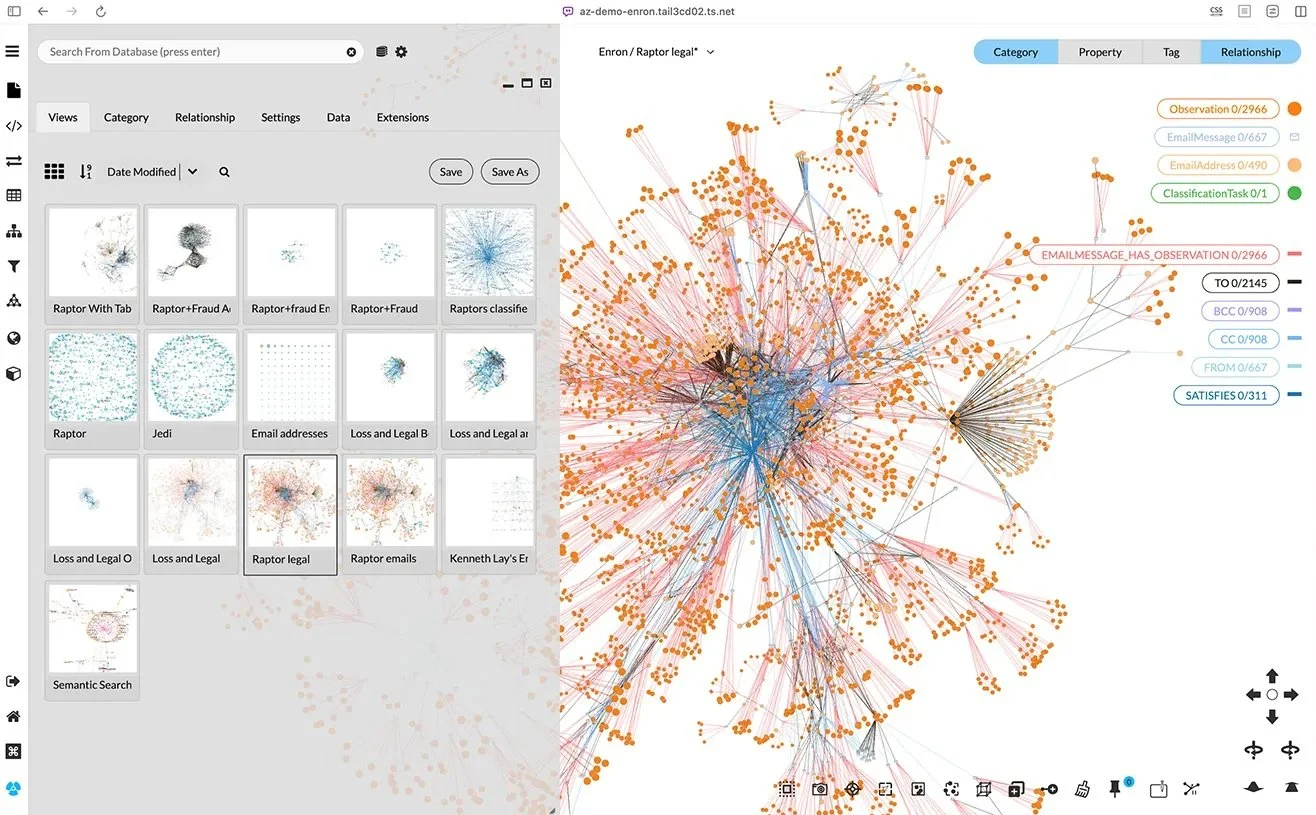
This extraction process worked reasonably well, although since time zones often must be inferred, one needs to implement sanity checks for date-time parsing. Moreover, the last reply of a chain might have the time zone, but the embedded messages may not.
The language model gets it right most of the time. We found gpt-4o can perform well for email chain extraction, while gpt-4o-mini fails. LLMs are rapidly evolving, and each has its own capabilities, so the choice of model will affect results. Again, that’s a compelling reason to be able to revisit the source information.
Thanks for reading! Visit kineviz.com or email me at ben at kineviz.com for more information. You can also reach me at our Discord here.